
Meta Introduces VL-JEPA: A New Direction for Vision-Language Models VL-JEPA learns by predicting internal concept representations instead of text, enabling stronger reasoning about the visual world with fewer parameters.
Researchers at Meta have introduced VL-JEPA, a new vision-language model built on a Joint Embedding Predictive Architecture (JEPA). Unlike traditional vision-language models that generate text token by token, VL-JEPA learns by predicting abstract representations of the world. This design shift makes VL-JEPA both more efficient and more capable. Despite using only about half the trainable parameters of comparable models, it delivers stronger performance across a wide range of tasks. More importantly, VL-JEPA supports diverse applications without requiring architectural changes, marking a fundamental move away from token generation toward genuine representation learning and physical world modeling.
Why Traditional Vision-Language Models Fall Short
Modern AI systems must be able to understand, reason about, and act within the physical world. Today’s dominant approach relies on large vision-language models (VLMs) that process images or video alongside text prompts and then generate textual responses autoregressively, one token at a time. While effective for many tasks, this approach has important limitations.
First, training is computationally expensive. These models must learn not only task-relevant semantics but also surface-level linguistic details such as phrasing and word choice. As a result, a significant amount of compute is spent generating token variations that do not meaningfully affect correctness.
Second, autoregressive decoding introduces latency, which is problematic for real-time applications such as live scene understanding or action tracking. Even when the underlying meaning is clear early on, the model must complete an entire decoding process before producing a usable output.
These inefficiencies motivate a different approach one that focuses on meaning rather than language form.
How VL-JEPA Works
VL-JEPA is built on the JEPA framework, which operates by predicting in latent (embedding) space rather than in raw data space. Instead of generating pixels or words, a JEPA model learns to predict the abstract representation of a target input from the representation of a related context input. By minimizing prediction error in this embedding space, the model learns high-level semantic concepts while ignoring unpredictable surface-level noise.
Originally proposed by Yann LeCun, JEPA has already been applied to images (I-JEPA) and video (V-JEPA). VL-JEPA extends this idea to joint vision and language modeling.
Architecture Overview
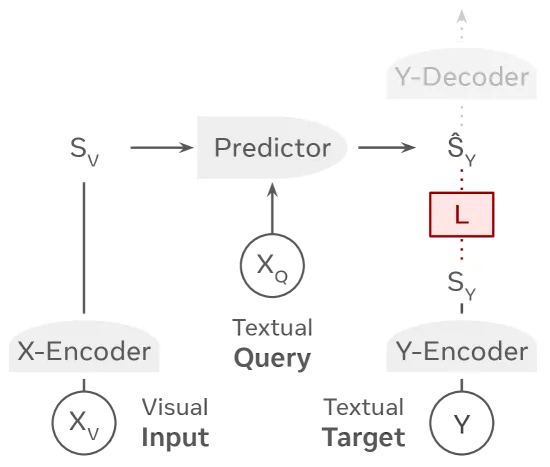
VL-JEPA consists of three main components:
- X-Encoder: Based on the V-JEPA 2 model, this encoder compresses high-dimensional visual inputs such as video frames into compact embeddings.
- Text embedding module: The textual query is tokenized, embedded, and concatenated with the visual embedding to define the task context.
- Predictor: Initialized using transformer layers from Llama 3, the predictor takes the combined visual and textual context and predicts the embedding of the target answer.
Crucially, the predictor does not generate text. It predicts the entire semantic concept of the answer in one step.
During training, the predicted embedding is compared to a target embedding produced by the Y-Encoder (initialized with EmbeddingGemma). The model learns by minimizing the distance between these embeddings. When human-readable output is required such as in visual question answering a separate decoder translates the predicted embedding into text.
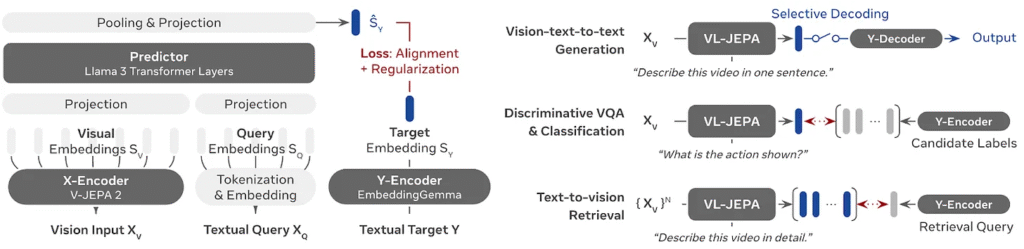
Why Predicting Embeddings Is More Efficient
Embedding-based prediction offers several key advantages:
- Reduced training complexity: The model is not forced to learn every surface detail of language. Semantically equivalent answers like “the lamp is turned off” and “the room will go dark” may differ greatly in token space, but they lie close together in embedding space.
- No heavy decoder during training: Since the model is non-generative by default, it avoids the computational overhead of full token reconstruction.
- Continuous semantic monitoring: Because VL-JEPA is non-autoregressive, it can produce a stream of “thought vectors” over time. In online settings, the system can monitor semantic changes and only invoke text decoding when necessary.
This makes VL-JEPA especially well-suited for real-time and streaming applications.
Training Strategy
VL-JEPA is trained in two stages:
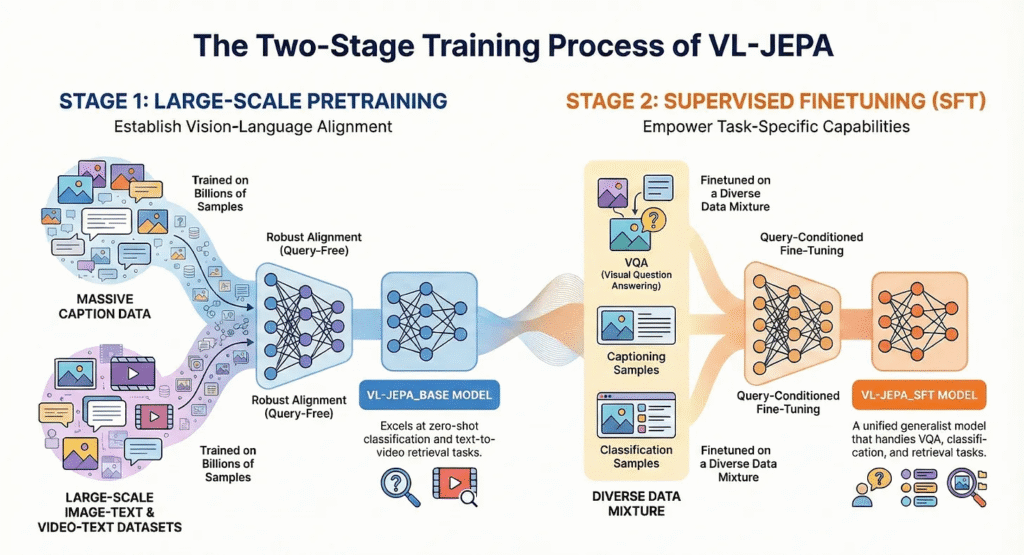
1. Query-Free Pretraining
In the first stage, the model learns broad vision-language alignment using large-scale image-text and video-text datasets. This produces VL-JEPA_BASE, which excels at zero-shot tasks such as video classification and retrieval.
2. Supervised Fine-Tuning
In the second stage, the model is trained in a query-conditioned setting using a mix of visual question answering, captioning, and classification data. A portion of the pretraining data is retained to prevent catastrophic forgetting. The resulting VL-JEPA_SFT functions as a unified generalist model capable of answering questions, counting objects, and reasoning about scenes.
Performance and Results
Meta evaluated VL-JEPA across a broad set of benchmarks, including eight video classification and eight video retrieval datasets. The model was compared against strong generalist baselines such as CLIP, SigLIP2, and Perception Encoder, as well as specialist models tuned for individual tasks.
- In zero-shot classification, VL-JEPA_BASE achieved higher average accuracy than the strongest baseline.
- In video retrieval, it delivered higher average recall.
- The model performed particularly well on motion-centric tasks, with slightly weaker results on appearance-centric benchmarks due to less exposure to image-text data during training.
After supervised fine-tuning, VL-JEPA_SFT closed this gap and achieved performance approaching that of specialist models. In visual question answering, VL-JEPA_SFT matched the performance of established VLMs such as InstructBLIP and Qwen-VL despite using only 1.6 billion parameters, compared to 7–13 billion in competing models. Most notably, in world modeling tasks where a model must infer the action connecting an initial state to a final state VL-JEPA achieved a new state-of-the-art accuracy of 65.7%, outperforming much larger frontier models including GPT-4o, Gemini-2.0, and Qwen2.5-VL-72B.
Implications
VL-JEPA demonstrates that generating language tokens is not always the best path to intelligence. Many real-world applications require systems that understand the environment and act appropriately not ones that produce fluent text. For these use cases, JEPA-based models offer a compelling alternative: more efficient training, lower latency, and stronger world understanding. VL-JEPA suggests a future in which AI systems reason in concepts first and only translate those concepts into language when needed.


GIPHY App Key not set. Please check settings