
Google just released Gemini 2.5 Flash-Lite, and it might be exactly what developers have been waiting for: an AI model that’s fast, smart, and won’t drain your wallet.
The Developer’s Dilemma
Anyone building with AI knows the struggle. You need a model that’s powerful enough to handle real tasks, fast enough to keep users happy, and affordable enough that you won’t go bankrupt paying for API calls. Until now, picking two out of three was considered lucky.
Gemini 2.5 Flash-Lite promises to solve this triangle of frustration.
Speed That Actually Matters
Google claims this model is faster than their previous “speedy” models—and if true, that’s significant. For applications like real-time translation, customer service chatbots, or any tool where delays kill the user experience, speed isn’t just nice to have, it’s essential.
When users expect instant responses, a model that takes several seconds to think becomes unusable, no matter how brilliant its output.
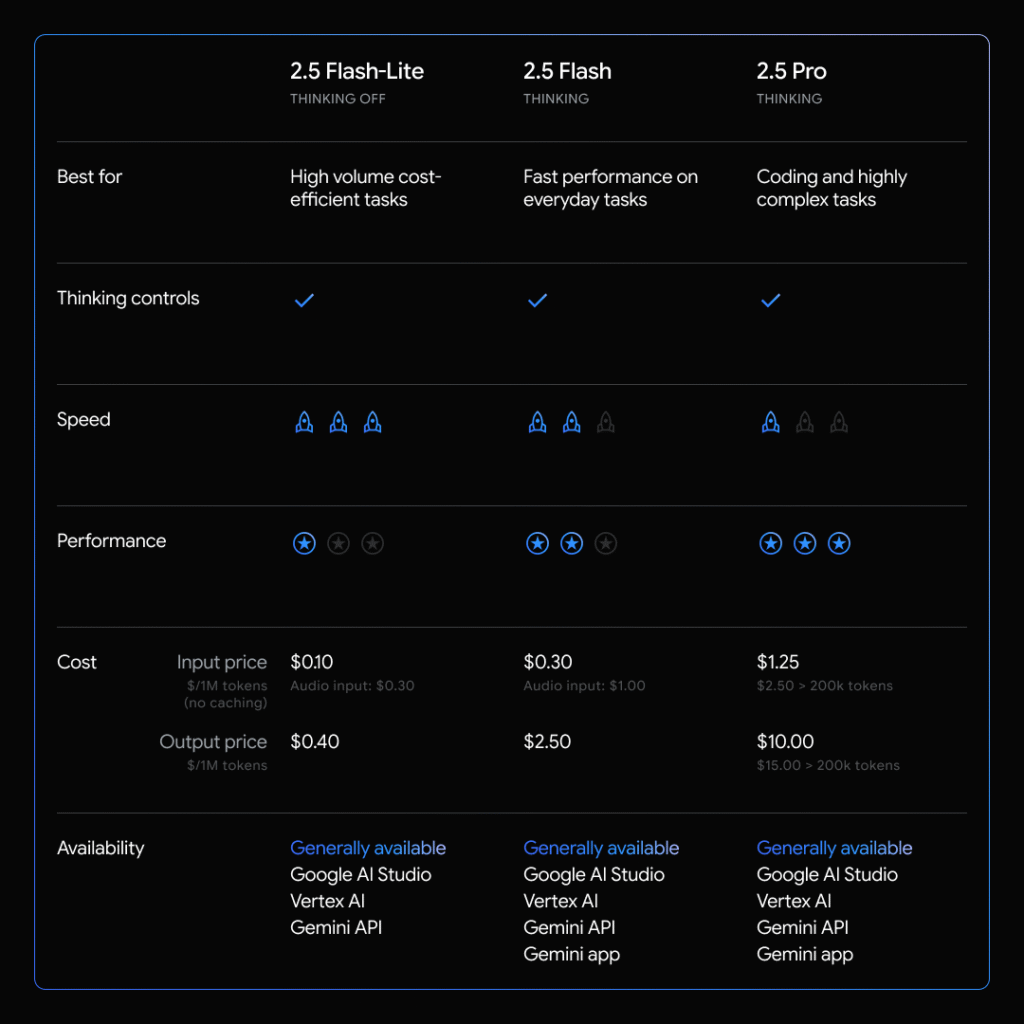
Pricing That Changes Everything
Here’s where things get interesting: $0.10 per million input tokens and $0.40 per million output tokens.
To put that in perspective, processing a million words costs just 10 cents. That’s the kind of pricing that fundamentally changes how you approach development. Instead of carefully rationing every API call, you can actually let your application work freely.
This pricing democratizes AI development. Solo developers and small teams can now build applications that previously only made financial sense for companies with deep pockets.
Smart Enough to Matter
The obvious question: if it’s cheap and fast, is it actually good? Google says yes, claiming Gemini 2.5 Flash-Lite outperforms its predecessors across reasoning, coding, and multimodal understanding (images and audio).
It also maintains that impressive one million token context window, meaning you can feed it entire codebases, lengthy documents, or hours of transcripts without hitting limits.
Real Companies, Real Results
The proof is in the implementation. Companies are already using Flash-Lite for demanding applications:
- Satlyt runs it on satellites to diagnose orbital problems, reducing delays and conserving power
- HeyGen uses it to translate videos into over 180 languages
- DocsHound automatically generates technical documentation from product demo videos
That last example is particularly compelling watching videos and creating accurate technical docs requires sophisticated understanding across multiple modalities. If Flash-Lite can handle that reliably, it’s clearly more than just a budget option.
Getting Started
You can start using Gemini 2.5 Flash-Lite immediately through Google AI Studio or Vertex AI. Just specify “gemini-2.5-flash-lite” in your code.
Important note: If you’re currently using the preview version, migrate to the new model name before August 25th Google is retiring the old version.
Why This Matters
Gemini 2.5 Flash-Lite isn’t just another incremental model update. It’s potentially a shift in who gets to build meaningful AI applications. When the cost barrier drops this dramatically while maintaining performance, it opens the door for innovation from unexpected places.
The most interesting AI applications often come from developers who understand specific problems intimately not necessarily those with the biggest budgets. Flash-Lite might finally give those developers the tools they need to build solutions that actually matter.


GIPHY App Key not set. Please check settings