
Artificial Intelligence (AI) has advanced rapidly in recent years. We now see AI writing essays, generating images, coding applications, and even assisting scientists in research. But there has always been one major limitation reasoning.
Reasoning is the process of thinking step by step to solve a problem. For humans, this is natural: when solving a tough math question, we usually don’t get the answer instantly. Instead, we go through a process collecting information, writing down steps, testing possibilities, and checking our work.
For AI models, however, reasoning has always been a difficult skill to master.
The Old Way: Teaching AI Step by Step
Traditionally, AI has been trained to reason by imitating humans. Researchers show the model thousands (or even millions) of examples of how to solve a problem step by step. For instance, if the task is to solve an equation, the AI would be trained with examples of every stage: rearranging terms, simplifying, and finally finding the answer.
While this method works, it has serious drawbacks:
- Time-consuming → Requires huge amounts of human-created examples.
- Limited by human bias → AI can only learn the reasoning styles shown to it.
- Rigid → Models may struggle with new or unusual problems not covered in the training data.
This means AI was only as good as the teachers who guided it.
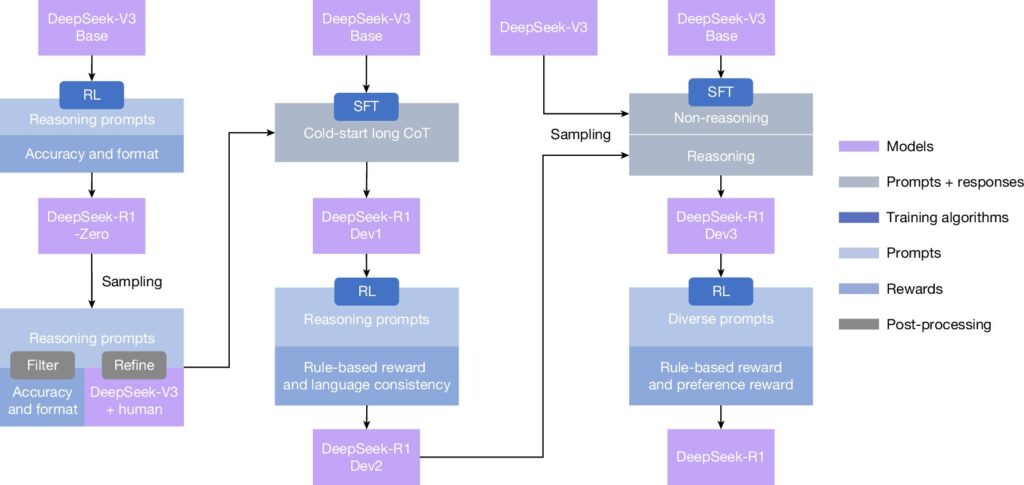
The New Way: DeepSeek’s Reinforcement Learning Approach
Researchers at DeepSeek AI, a Chinese AI company, decided to try a different approach. Instead of teaching every single step, they let the model figure things out by itself using a method called reinforcement learning.
Reinforcement learning works a lot like how we train pets:
- If the AI gives a correct final answer, it receives a reward signal.
- If the answer is wrong, it gets no reward.
That’s it no step-by-step guidance.
Surprisingly, with enough practice, the model (called R1) started to develop its own reasoning skills. It learned to:
- Double-check its answers before finalizing them.
- Try different strategies when stuck.
- Even use natural language like “wait” while reconsidering its process—almost like thinking out loud.
This shows that AI can self-develop problem-solving strategies when given the right incentives, instead of simply copying humans.
Impressive Results
The results were remarkable:
- R1 outperformed older AI models trained with human demonstrations.
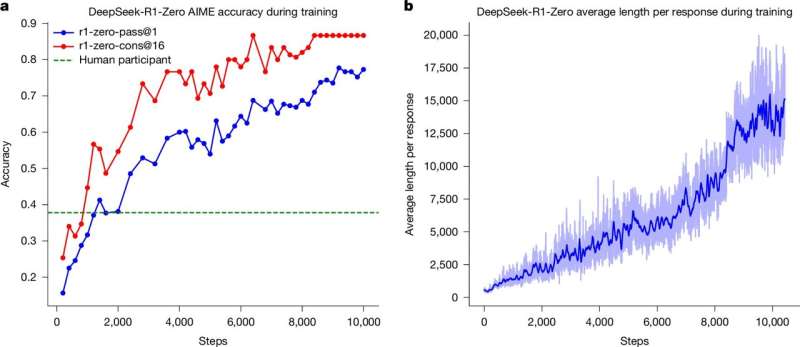
- On the American Invitational Mathematics Examination (AIME) 2024, one of the hardest math competitions for high school students, R1 scored an accuracy of 86.7%.
- It also showed strong performance in coding and science tasks, areas where step-by-step logical reasoning is essential.
This is the first time an AI model trained mainly through reinforcement learning has reached such a high level of reasoning ability.
Challenges and Limitations
Despite its success, R1 is not perfect yet. The researchers noted a few issues:
- When given non-English prompts, it sometimes mixed languages in its answers.
- It occasionally overcomplicated simple problems, wasting time on unnecessary steps.
These challenges highlight that while AI reasoning has improved, it still needs refinement before being fully reliable.
Why This Matters
The breakthrough with DeepSeek R1 could change how AI models are trained in the future. Instead of relying on massive human-annotated datasets, we might simply provide AI with the right goals and rewards—letting it discover smarter ways to solve problems on its own.
This shift could lead to:
- More autonomous AI → Models that don’t just mimic humans but actually think for themselves.
- Faster progress → Less dependence on human teaching, allowing models to improve more quickly.
- Smarter problem-solving → Especially in fields like science, engineering, and mathematics, where creative reasoning is key.
In short, DeepSeek’s R1 is not just another AI model it represents a new chapter in AI development, one where machines may begin to reason independently, just as humans do
For more information:DeepSeek-R1 incentivizes reasoning in LLMs through reinforcement learning


GIPHY App Key not set. Please check settings